
就在很多人还在争论“推荐算法是不是黑箱”的时候,马斯克直接把桌子掀了。
X(原 Twitter)把驱动「For You」信息流的核心推荐算法,整个开源了。
不是论文,不是 PPT,不是“简化版 Demo”,而是真实在生产环境跑的推荐系统架构。
代码仓库上线 7 个小时,Star 数已经冲到 2.6K,而且还在持续上涨。
这件事,在推荐系统、AI、内容平台这几个圈子里,分量非常重。
下面我们就基于官方 README 的完整内容,来系统拆解一下:
👉 X 的推荐算法到底是怎么工作的?
👉 它为什么敢开源?
👉 这套系统在工程和模型层面,到底牛在哪?
项目开源:https://github.com/xai-org/x-algorithm
终于能正常打开Github了:https://zhiliaole.top/archives/1763544164789
一、先说结论:这是一个“现代推荐系统”的标准答案
一句话总结 X 的 For You 推荐算法:
用一个 Grok-based Transformer,统一完成候选内容的理解、评分和排序,彻底干掉人工特征工程。
它的几个核心特征非常鲜明:
同时推荐
你关注的人发的内容(In-Network)
你没关注、但算法认为你可能感兴趣的内容(Out-of-Network)
不靠规则、不靠人工特征
全部交给 Transformer 去“理解你这个人”
而且,这不是“研究系统”,而是真实服务数亿用户的工程级实现。
先上整体架构:
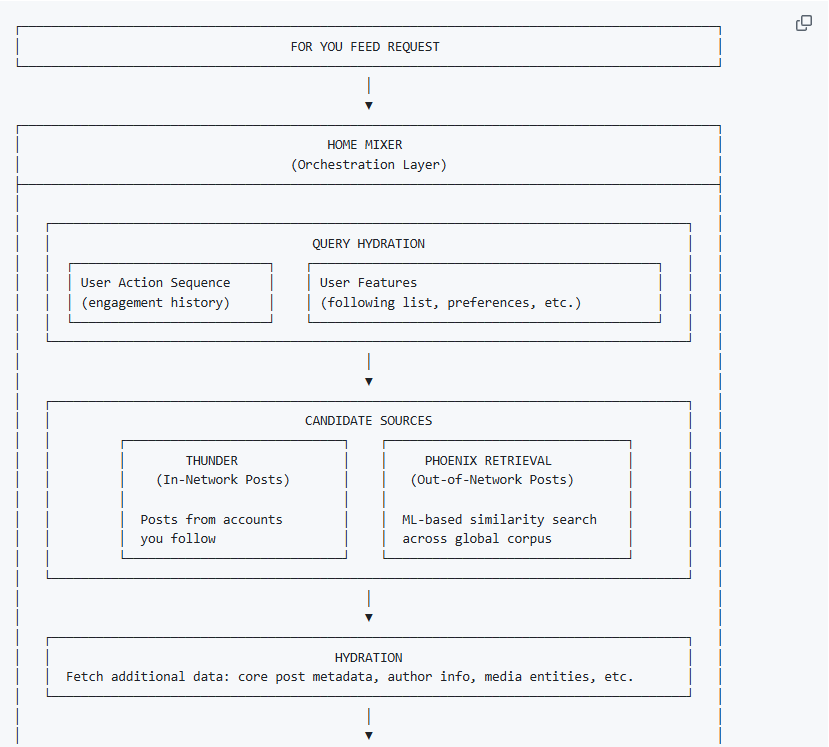
二、X 的 For You 信息流,整体是怎么跑起来的?
整个系统可以理解为一条高度工程化的推荐流水线,由一个核心组件统一调度。
1️⃣ 总控:Home Mixer(信息流总指挥)
当你打开 X 的「For You」页面时:
请求首先进入 Home Mixer
它不负责算分
只负责:
👉 把所有模块串起来,保证推荐流程稳定、高效、可扩展
2️⃣ 用户上下文:算法先“读懂你”
在推荐任何内容之前,系统会先补全你的信息:
最近点过什么
点赞、转发、回复过什么
关注了哪些账号
有哪些偏好设置
注意一个关键点:
这些信息不是喂给规则的,而是直接作为 Transformer 的输入上下文。
三、候选内容从哪来?两条路,一起算
(1)Thunder:你关注的人在发什么
Thunder 是一个内存级、实时更新的帖子系统:
Kafka 实时消费所有发帖/删帖事件
按用户维护最近内容
毫秒级返回结果
作用只有一个:
👉 极快地拿到“你关注的人刚发了什么”
(2)Phoenix Retrieval:你可能会喜欢什么
真正“算法味”最重的部分,在这里。
这是一个 Two-Tower 检索模型:
用户塔:
把你的行为历史 → 编码成向量内容塔:
把全站帖子 → 编码成向量用向量相似度
👉 从全球内容池里捞出你可能感兴趣的帖子
也就是说:
你刷到的很多内容,作者你可能从没关注过,但模型觉得“你大概率会点”。
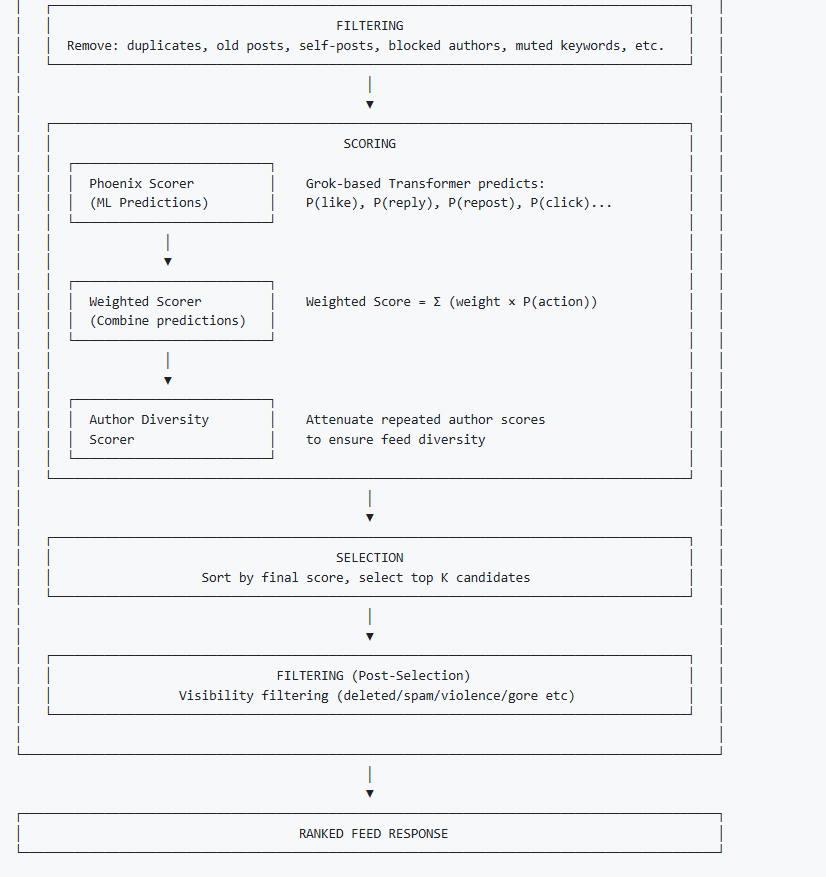
四、真正的核心:Grok Transformer 怎么给内容打分?
所有候选内容,最终都会交给 Phoenix Ranking Transformer。
它不是输出一个“相关性分数”
而是一次性预测你可能做的 一整套行为:
点赞?
回复?
转发?
点开?
看视频?
点进作者主页?
不感兴趣?
拉黑?
举报?
模型会输出一组概率,比如:
P(like)
P(repost)
P(reply)
P(click)
P(block)
P(report)
...
然后系统怎么决定“推不推”?
很简单,但也很狠:
最终分数 = Σ(行为概率 × 权重)
正向行为 → 正权重
负向行为(拉黑、举报)→ 负权重
👉 你越可能讨厌的内容,分数直接被拉下去。
五、一个非常“工程师”的设计:候选隔离(Candidate Isolation)
这是 README 里一个非常值得注意的设计点。
在 Transformer 推理阶段:
候选内容之间,不能互相“看到”对方。
也就是说:
每条帖子的分数
只取决于
👉 你
👉 你和这条帖子的关系
而不取决于“同一批次里还有谁”。
这带来的好处非常实在:
分数稳定
可缓存
可复用
不会因为 batch 不同而抖动
这是典型的工业级推荐系统思维。
六、过滤不是一层,是“两道防线”
第一层:打分前过滤
比如:
重复内容
你自己的帖子
被你拉黑/屏蔽的作者
已经刷到过的内容
订阅不可见内容
关键词屏蔽
第二层:Top-K 之后再过滤
比如:
已删除
垃圾信息
暴力、血腥
会话线程重复刷屏
七、最激进的一点:完全不要人工特征
README 里说得非常直接:
We have eliminated every single hand-engineered feature.
这在大厂推荐系统里,其实是非常“反常识”的。
但 X 选择了一条非常明确的路线:
不再维护复杂的特征工程
不再调一堆 if-else 规则
让模型直接学“什么对你重要”
这意味着:
系统复杂度 ↓
解释成本 ↑
对模型能力的要求 ↑↑↑
八、为什么这次开源,意义真的不小?
因为它至少做了三件以前没人敢做的事:
把真实生产推荐系统开源
把“算法黑箱”摊在桌面上
给整个行业一个可对照的工程范式
不管你喜不喜欢 X 的推荐结果,这件事本身,确实很“马斯克”。
最后
这不是一个“给外行看的算法项目”,
而是一个:
“你真想学推荐系统,绕不开的工程级样本。”